Transformer
자연어처리에서 트랜스포머가 Vaswani et al.2017, 'Attention is all you need' 페이퍼로 발표되고 이후 영향력이 상당합니다.
pretrained-language model이 트랜스포머를 사용하기 때문입니다.
그래서 트랜스포머를 장인이 만든 장독대라고 비유하고 사전학습 언어 모델을 양념장으로 비유해보고 싶습니다.
그동안의 주요 모델의 역사가 RNN-> RNN+LSTM->LSTM+Attention -> Transformer으로 흘렀고 여러 연구진들의 경험을 거쳐 나타난 모델이이기 때문입니다.
Transfomer의 아키텍쳐는 attetnion만 이용해서 인코딩과 디코딩을 구성한다는 것이 특징입니다.
이전 seq2seq 포스팅에 이어서 Attention을 먼저 알아보고 다음으로 트랜스포머를 알아보겠습니다.
1. Attention
기존 RNN의 단점은 문맥 벡터가 하나로만 결정되어 긴 문장에서 앞 단어들의 정보가 손실된다는 것입니다.
attetnion은 이를 보완하고자 새로운 키포인트가 있습니다.
디코더에서 단어를 예측할 때마다 인코더의 문장을 참고합니다.
이때, 인코더의 문장을 참고하되 디코더에서 예측할 단어마다 집중해야 할 문맥을 참고합니다.
attention 과정

위에 그림에서 'the black cat drannk milk'라는 문장이 있습니다.
먼저, 인코더에서 각 토큰은 히든 벡터로 표상되고 이의 행렬로 합쳐져 h7 로 만들어놓습니다.


문장 내에서 필요 정보 집중
위의 그림은 차례대로 디코더 2번째 토큰 'chat', 3번째 토큰 'noir'를 구하는 과정입니다.
'chat'은 인코더에서 소프트맥스로 변환된 값 중에서 'cat'과 유사도가 가장 높게 나타납니다.
'noir'는 인코더에서 'black'과 유사도가 가장 높게 나타납니다.
이렇게 디코더의 출력 토큰이 예측하기 위해서 소스 문장의 유사도가 높은 토큰을 때마다 참고하다보니 장기 의존성 문제를 보완할 수 있습니다.
즉, 인코더 모델의 hidden state vector hi와 attetion weight ai를 가중합하여 attention vector ai를 만듭니다.
이때, attention vector ai는 문장에서 단어의 문맥 정보를 가지고 있으므로 context vector라고도 합니다.
ai는 이제 디코더 벡터 si에 결합되면서 최종 출력 yi 가 됩니다.
Context Vector는 수치로 표현되었는데 어떻게 문맥을 가졌을까?
위의 'the black cat'를 보면 정관사 'the', 형용사 'black', 명사 'cat'은 임의의 순서가 아니라 문법적 수식을 위해 위치가 결정됩니다.
정관사와 형용사가 명사를 수식하려면 명사 앞에 위치해야 하는데 정관사와 형용사가 동시에 한 개의 명사를 수식할 때, '정관사+형용사' 순서로 명사를 수식합니다. 그래서 'black the cat'은 문법적 오류입니다.
이처럼 자연어의 정보 손실을 줄이고 적합한 맥락을 집중하려 했던 어텐션의 기법은,
어떻게 보면 사람의 언어 현상 플로우를 모방했기 때문에 당연한 결과로 볼 수 있을 것 같습니다.
2.Transformer
트랜스포머는 어텐션을 어떻게 이용할까?
아래가 트랜스포머 전체 구조입니다.
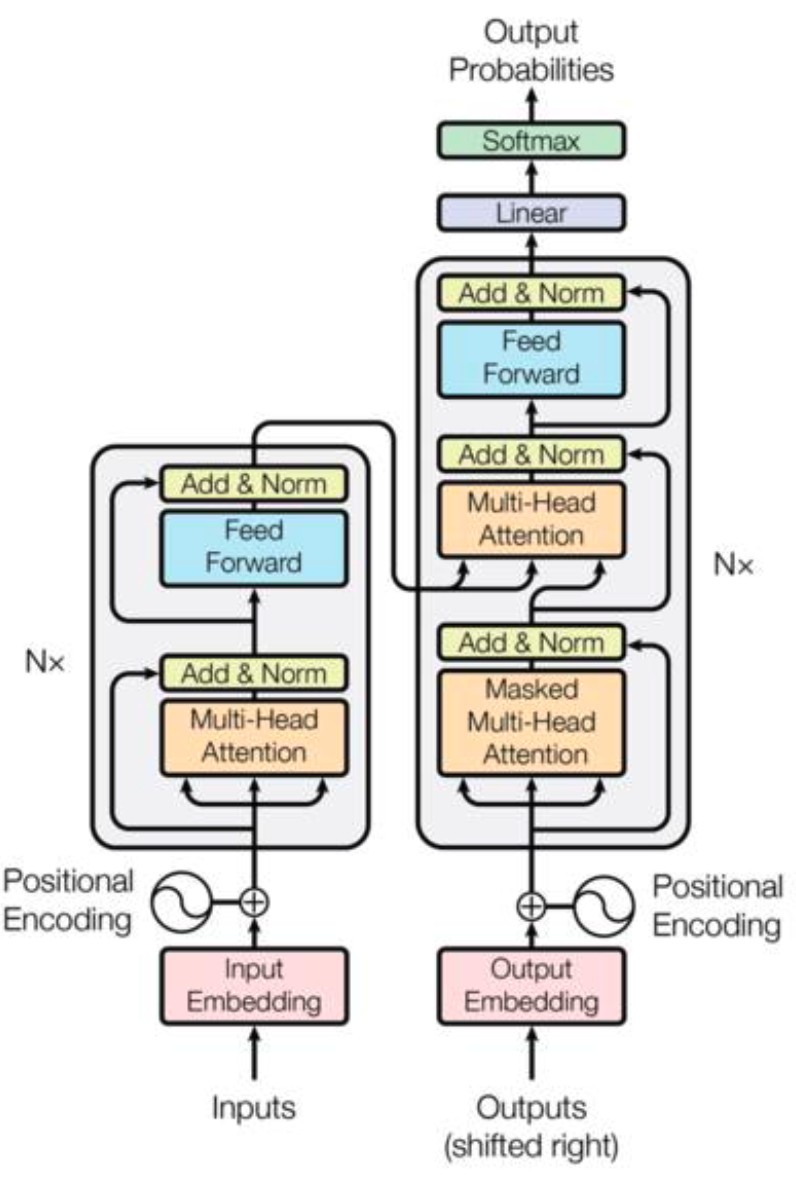
이전에 어텐션은 인코더에서만 사용된 것과 달리, 인코더와 디코더 모두 사용됩니다.
단, 이전에 어텐션 그대로 사용하는 것이 아니라 다양한 종류의 어텐션을 사용합니다.
인코더에서 Multi-Head Self-Attention, 디코더에서 Masked Multi-Head Self-Attention, Multi-Head Attention입니다.
Self-Attention

'The animal didn't cross the street because it was too tired.'
위의 문장 내에서 대명사 'it'의 선행사는 'the animal'입니다.
이처럼 셀프 어텐션은 입력 문장 내에서 단어 간의 유사도를 계산하여 선행사와 대명사가 서로 지칭하는 관게임을 알아내는 것입니다.

기존 어텐션에서 Queries, Keys, Values 구성은 디코더 Q, 인코더 K와 V였습니다.
그래서 출력할 토큰 벡터 Q의 유사한 값 K, V를 찾았습니다.
셀프어텐션에서 Q, K, V 모두 인코더에서 기인합니다.
인코더의 Q와 유사한 K, V 값을 찾다보니 위에서 'the animal'과 'it' 연관성을 가져올 수 있는 것입니다.
Muti-head Attention

'Attention is all you need' 저자는 어텐션을 한 번 동작하기 보다 나눠서 여러 번 하는 것으로 설계했습니다.
그래서 512차원 벡터를 num_head 8로 나눠서 64차원 Q, K, V를 구합니다.
64차원 어텐션이 8개가 병렬로 진행하는 것입니다.

이러한 의도는 기존 어텐션의 기조인 손실없이 문맥을 얻기 위해 계산 구하는 과정을 쪼갰던 것과 일치합니다.
RNN이 컨텍스트 벡터 총 1개를 받는 것이 아니라 어텐션은 컨텍스트 벡터를 디코더에서 각각 받으려고 한 것처럼,
멀티헤드 어텐션도 기존 어텐션보다 단어마다 받던 것을 임의의 수치로 더 쪼개서 정보를 가져오고 합산합니다.
문장이 길수록 그만큼 syntax 구조가 복잡해지고 coreference 등이 나타날 수 있어 복잡하기 때문에 이러한 시도를 한 것 같습니다.
위의 예시에서 'it'이 선행사를 찾는 coreference, 그리고 it의 지배소인 서술어 'tired'를 찾는 syntax 문제를 해결한 것입니다.
Positional Encoding
트랜스포머는 이전 RNN처럼 순서대로 시퀀스를 받는 것이 아닙니다.
그래서 임베딩 벡터에 positioanl encoding을 추가합니다.
위치 정보는 언어학적으로도 문법이 담겨져 있기 때문에 상당히 중요합니다.
같은 단어라도 다른 단어와의 맥락에 따라 의미가 달라집니다.
한국어는 head-final language에 속하여 마지막 위치의 단어가 앞에 단어들을 포괄하는 큰 의미를 가집니다.
예를 들어, '사과 농장', '대국민 사과' 짧은 명사구에서도 맥락이 다릅니다.
특히, '사과'가 접사와 어미가 없더라도 서술성 명사이기 때문에 용서를 구하는 '사과'로 해석됩니다.


이처럼 트랜스포머의 전체 구조 컨셉과 내부의 작은 기법과 아이디어들은 언어 현상을 최대한 반영하기 위한 전략으로 볼 수 있습니다.
그만큼 사람이 쓰는 자연어에는 수많은 인지와 합의가 응축된 현상인 것 같습니다.
이러한 응축된 언어를 담아내기에 트랜스포머라는 항아리는 연구자들에게 꼭 필요한 항아리일 것입니다.
Reference
Vaswani et al.2017, 'Attention is all you need'
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
http://docs.likejazz.com/attention/https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/10/06/attention/
Attention Mechanism 시각화 · The Missing Papers
Attention Mechanism 시각화 09 Jul 2018 Seq2Seq는 시퀀스 데이터를 처리하는데 좋은 결과를 보여주지만 여전히 입력 시퀀스가 길 경우 장기 의존성long term dependencies 문제가 있다. 어텐션 메커니즘Attention M
docs.likejazz.com
어텐션 매커니즘 · ratsgo's blog
이번 글에서는 딥러닝 모델이 특정 벡터에 주목하게 만들어 모델의 성능을 높이는 기법인 어텐션(attention) 매커니즘에 대해 살펴보도록 하겠습니다. 이 글은 미국 스탠포드 대학의 CS224d 강의와
ratsgo.github.io
'자연어처리' 카테고리의 다른 글
| Pre-trained Language model - 만능 양념장 (0) | 2021.06.11 |
|---|---|
| MRC - 언어능력평가 (0) | 2021.06.09 |
| Seq2Seq - 입력과 출력 (0) | 2021.05.22 |
| RNN & LSTM - 시퀀셜 데이터 학습 (1) | 2021.05.22 |
| Word2Vec - 단어를 숫자로 (0) | 2021.05.19 |



