Pre-trained Language Model
백종원 만능 양념장이 어떤 요리에도 잘 어울리고 맛을 내는 것처럼,
만능 양념장처럼 사전학습 언어모델이 자연어처리의 모든 태스크에 뛰어난 성능을 보여주고 있습니다.
이전 포스팅에 소개한 트랜스포머라는 항아리에 담근 만능 양념장은 모든 기록을 갈아치웁니다.

트랜스포머 아키텍처는 인코더 6개, 디코더 6개로 이루어졌는데 이를 활용한 트랜스포머 기반 GPT를 알아보겠습니다.
다음으로 현재 공개된 한국어 특화 GPT와 BERT 현황을 알아보겠습니다.
GPT(Geneartive Pre-trained Transformer)
Open AI에서 발표한 GPT는 GPT-1부터 Few-shot Learning의 GPT-3까지 공개했습니다.
전반적인 디코더 방식의 학습 구조는 비슷하고 데이터 규모, 파라미터 개수가 더 거대해졌습니다.
GPT는 단방향 학습을 진행해 입력 문장에 다음 시퀀스를 예측하여 출력합니다.
그리고 다시 모델의 출력을 다시 받아 다음 단어를 예측합니다.
이런 모델의 auto-regression 아이디어는 생성 기반에 더 좋은 성능을 보여주고 있습니다.


GPT-2 아키텍처는 인코더가 없는 디코더만으로 이루어진 스택 구조 트랜스포머 구조입니다.
BERT가 쓰는 Self-Attention과 다르게 Maseked Self-Attention를 사용하는 것이 특징입니다.
보통의 Self-Attention은 문장 전체 토큰을 고려합니다.
Self-Attention 기준 토큰의 오른쪽 방향 토큰도 참고를 하지만 Maseked Self-Attention은 오른쪽 토큰을 참고하지 않는 것입니다.
이 방법이 auto-regression 아이디어를 구체화하기 위한 일부입니다.

이렇게 사전학습된 모델은 다운스트림 태스크를 위한 전이학습(Transfer Learning)으로 활용됩니다.
이때 마지막 파인튜닝(Fine-tuning)을 통해 classification, entailmnet, similarity, multiple choice 등 여러 자연어처리 태스크에 활용될 수 있는 양념장입니다.
BERT(Bidirectional Encoder Representations from Transfomers)
BERT가 GPT와 트랜스포머 구조에서 다른 점은 인코더를 사용한다는 점입니다.
그리고 입력 토큰에 문맥 정보를 입힌 벡터로 만들기 위해 Mask LM, Next sentence prediction 태스크를 진행하는 것이 큰 특징입니다.
이 학습 태스크가 GPT와 달리 BERT는 양방향 학습을 하도록 한 것입니다.
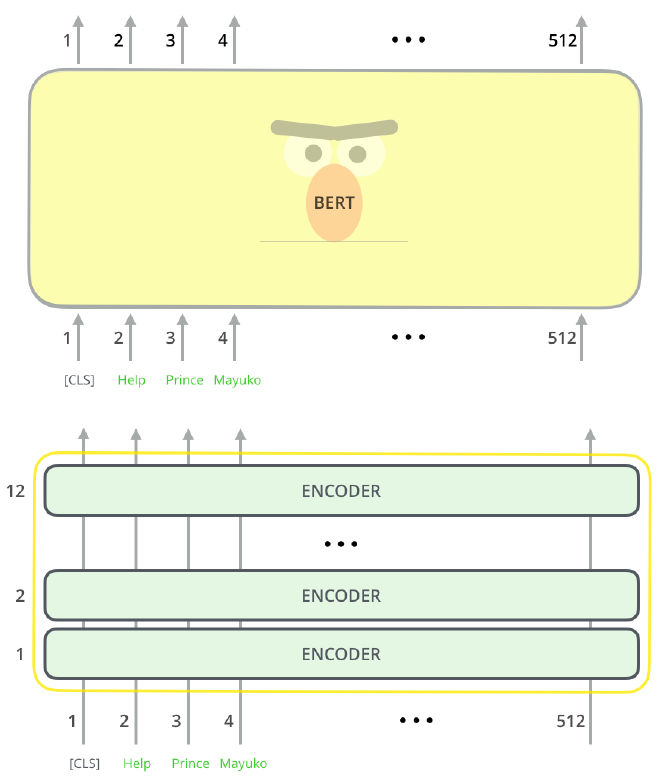
인코더 스택은 BERT 학습 데이터 사이즈에 따라 달라집니다.
BERT Base는 인코더 레이어 12개, BERT Large는 24개입니다.
BERT 인코더 입력의 최대 토큰 길이는 512입니다.
그래서 BERT를 사용할 때, 가변 길이를 늘리는 실험을 진행한 페이퍼도 있습니다.

컨텍스트 벡터를 만들기 위해서 Mask LM 훈련을 진행합니다.
GPT는 오른쪽 토큰을 볼 수 없도록 막았는데, BERT는 전체 문장을 보여주고 임의의 토큰만 가립니다.
위 그림에서 [MASK] 토큰이 있는데, 임의의 토큰 포지션을 가리고 맞춰야 합니다.
한 번만 진행하면 전체 문맥을 담기 어려우니 여러 번 진행하여 컨텍스트 벡터를 만듭니다.

다음으로 문장 간의 관계 학습을 위해 [SEP]이라는 special token을 만들어서 A문장과 B문장을 예측하는 사전학습을 진행합니다.
문장의 시작인 [CLS]와 문장의 종결인 [SEP]까지 Segmant 임베딩이 만들어지는데 사전 학습을 위한 세팅입니다.

사전학습 언어모델을 사용하여 기존 자연어처리 다운스트림 태스크에 Fine-Tuning을 적용한 플로우입니다.
각 태스크에서 뛰어난 성능을 보여줬습니다. 특히, BERT_LARGE가 BERT_BASE보다 스코어가 높습니다.
여기까지가 대표적인 사전학습 언어모델 GPT와 BERT였고 한국인 연구자들이 한국어 데이터로 특화한 한국어 사전학습 언어모델을 소개합니다.
한국어 GPT
공개된 한국어 GPT-2는 SKT가 연구한 KoGPT2를 공개했습니다.
한국어 40GB 이상의 텍스트로 학습한 GPT-2 모델입니다.
김래선 외 4명, '롱테일 질의 확장을 위한 추출 및 생성 기반 모델', 제32회 한글 및 한국어 정보처리 학술대회, HCLT2020
제가 공저자로 참여했던 페이퍼로 연관검색어, 자동완성 등 질의 확장을 위한 추출 및 생성 기반 모델로 KoGPT2를 이용했습니다.
오픈소스의 중요성이 연구 확장에 도움이 되는 것을 직접 느껴본 사례입니다.

최근에 네이버에서 GPT-3보다 6,500배 많은 대규모 데이터로 사전학습 언어모델 Hyper Clova를 공개했습니다.
관련하여 SKT와 카카오, LG, KT 등 여러 회사에서 대규모의 사전학습 언어모델을 연구 중이라고 합니다.
해외 구글, Open AI가 아닌 국내 기업들이 준비한다는 점에서 한국어 언어처리의 주도권을 가져올 수 있을 것 같아 다행입니다.
하지만, 초거대 규모의 언어모델 연구에는 학생들에게 접근하기 쉽지 않으므로 KR-BERT와 같이 리소스가 적게 드는 언어모델 연구도 활발해졌으면 좋겟습니다.
한국어 BERT
기존에 공개된 Google Multi-lingual BERT는 다국어 기반으로 학습되었습니다.
이에 한국어 데이터로만 학습한 BERT가 연구자들 사이에서 공개되었습니다.
기존 Google BERT 성능을 이겼기 때문에 데이터와 토크나이저가 중요함을 알게 되었습니다.
한국어 BERT 현황

위 표는 서울대 신효필 교수님 연구실에서 발표한 KR-BERT 깃헙에서 인용했습니다.
이와 관련한 논문은 Lee et al.2020 'KR-BERT: A Small-Scale Korean-Specific Language Model' 입니다.
주요 성과는 현재 사전 학습 모델에 훈련에 들어간 10분의 1인 적은 양 데이터로도 성능을 낼 수 있었습니다.
적은 양으로도 성능이 좋았던 것은 character 기반 표상 뿐만 아니라 sub-charcater 기반 표상도 반영할 수 있었기 때문입니다.
즉, 음절보다 더 쪼개는 음소를 사용한 것이 키포인트입니다.
sub-character 표상은 자체 개발한 BidirectionalWordPiece Tokenizer을 이용한 것입니다.

이는 한국어가 교착어로 morphological rich한 언어고 한글이 10,000개 이상의 음절을 쓰이기 때문입니다.
이러한 자소 조합의 음절은 음소로도 쪼개져야 하는 이유는 다음과 같습니다.
즉 예를 들어, '항아리에 담근 양념장'을 형태분석 하면 아래와 같습니다.
'항아리/명사 에/조사 담그/동사 ㄴ/관형형어미 양념장/명사'
위에서 sub-charcter가 필요한 것은 'ㄴ/관형형어미'와 일부 음소에 해당되는 형태소가 있기 때문입니다.
'ㄴ/관형형 어미'는 서술어가 명사를 수식할 수 있게 하는 형태소로 실제로 많이 쓰입니다.
즉, 토크나이저로 잘 쪼개져야 uniq 실질형태소가 잘 분리될 것이고 이를 바탕으로 활용과 파생 현상을 잘 이해하고 generation 태스크에 쓸 수 있을 것입니다. 위의 연구는 토크나이저로 형태소분석기를 사용한 것은 아니지만 sub-character 단위가 흡사 형태소 분석기 수준으로 성능을 낸 것으로 볼 수 있습니다.
이러한 추측은 위 테이플에서 KR-BERT가 적은 양으로 학습했어도 다른 ETRI, SKT 사전학습 언어모델과 비교했을 때, 일부 태스크에서 성능이 뛰어나거나 그에 준하는 성능이 나온 것 같습니다.
앞으로 사전학습 언어모델에 적용할 토크나이저에 대한 연구가 기대됩니다.
Opinion about GPT : GPT는 영어와 한국어 어느 언어에 더 성능이 좋을까?
GPT-3는 학습 데이터의 거대한 양으로 데이터의 sparse 문제도 해결하지만, GPT 기법 자체의 auto-regression 아이디어를 언어 특성과 제고해보겠습니다.
단, 두 언어의 학습 데이터가 같고 GPT-3처럼 초거대 규모 데이터 확보가 되지 않는다는 전제하입니다.
GPT 아이디어를 해석해보면, 텍스트를 좌에서 우로 읽는 언어들이 대부분이기에 인지적으로 합리적인 것 같습니다.
그런데, '영어와 한국어 어떤 것이 더 유리할까?'라는 고민이 들었습니다.
여기에서 영어가 head_initial인 것을 생각해볼 필요가 있을 것 같습니다.
head는 주위 단어들과의 관계로 상대적이기 때문에 어떤 단어가 head가 될 수 있는지 3가지 경우를 생각해봤습니다.
1) 문장에서 다른 어휘들을 지배하는 서술어가 head
2) 명사구에서 다른 명사를 포괄하는 명사가 head
3) 수식어와 피수식어 중에는 수식을 받는 피수식어가 head
영어는 head-initial 언어로 주어와 서술어가 문장 초반에 나옵니다.
(ex. I wrote the paper when the winter was coming.)
문장의 head는 문장 구조에 중요한 영향을 끼치고 핵심 의미를 담았습니다.
영어 문법 시간에 서술어에 따라 문장 구조(1~5형식)이 다름을 기억하실 수 있을 겁니다.
ex) give(4형식 동사) - I gave him a coke.
give가 온다면 뒤에 간접목적어, 직접 목적어가 나와야 함을 예측할 수 있습니다.
반면에 한국어는 head-final 언어로 서술어는 대부분 문장의 마지막에 나타납니다.
순차적으로 다음 단어가 생성될 때 한국어는 얼마나 확장할 수 있고 side-effect가 얼마나 클까요?
예시)나는 그에게 콜라를 줬다.
-x2 확장 예시
x0 나는 x1 그에게
x0 나는 x1 그에게 x2 인사를
x0 나는 x1 그에게 x2 인사를 x3 건넸다.
-x3 확장 예시
x0 나는 x1 그에게 x2 콜라를
x0 나는 x1 그에게 x2 콜라를 x3 샀다.
임의로 시퀀스 확장해봤는데, 문장의 intent가 give_coke에서 greet, sell_coke로 다양하게 바뀌는 것을 볼 수 있습니다.
다양해지는 인텐트로 봐도 한국어의 생성은 side-effect가 클 것 같습니다.
이러한 언어 특성 기반으로 영어가 한국어보다 GPT 성능 효과를 더 많이 받을 것 같습니다.
References
Lee et al.2020 'KR-BERT: A Small-Scale Korean-Specific Language Model'
KR-BERT: A Small-Scale Korean-Specific Language Model
Since the appearance of BERT, recent works including XLNet and RoBERTa utilize sentence embedding models pre-trained by large corpora and a large number of parameters. Because such models have large hardware and a huge amount of data, they take a long time
arxiv.org
https://jalammar.github.io/illustrated-gpt2/
The Illustrated GPT-2 (Visualizing Transformer Language Models)
Discussions: Hacker News (64 points, 3 comments), Reddit r/MachineLearning (219 points, 18 comments) Translations: Russian This year, we saw a dazzling application of machine learning. The OpenAI GPT-2 exhibited impressive ability of writing coherent and p
jalammar.github.io
Beyond 512 Tokens: Siamese Multi-depth Transformer-based Hierarchical Encoder for Long-Form Document Matching
Many natural language processing and information retrieval problems can be formalized as the task of semantic matching. Existing work in this area has been largely focused on matching between short texts (e.g., question answering), or between a short and a
arxiv.org
'자연어처리' 카테고리의 다른 글
| Transformer - 당신이 필요로 할 장독대 (0) | 2021.06.10 |
|---|---|
| MRC - 언어능력평가 (0) | 2021.06.09 |
| Seq2Seq - 입력과 출력 (0) | 2021.05.22 |
| RNN & LSTM - 시퀀셜 데이터 학습 (1) | 2021.05.22 |
| Word2Vec - 단어를 숫자로 (0) | 2021.05.19 |



